







With the rise of Large Language Models, chatbots are becoming an increasingly popular tool to provide information, answer questions, and engage users in meaningful conversations.
Chatbots are evolving rapidly, and Large Language Models (LLMs) are at the forefront of this change. The Retrieval-Augmented Generation (RAG) method lets us build chatbots that do not just sound conversational – they can leverage a vast knowledge base to give accurate and informative answers.
To tell us a bit about the topic, we have Filip Stefanovski – our Software Engineer with over 12 years of experience in a variety of technologies ranging from back-end to front-end. Over his years of experience, he has been involved in end-to-end software development lifecycle parts, which include understanding of business workflows and processes, software development, and deployment.
Filip is also one of the people who made our internal Polar Cape chatbot a reality. This chatbot helps us stay up to date with procedures and other administrative needs. Read all about it below as we dive deeper into LLMs and the RAG process.
Understanding Language Models
A language model is a statistical tool that learns the patterns of human language. At its core, it tries to predict the next word (or character, or word fragment called token) in a sequence, when given the words that came before or between. Essentially, it acts as an intelligent autocomplete system.
In its pure essence, a language model tries to model:
P(wm | wm−k,…,wm−1)
For a given context of previous words (or surrounding words) wm−k,…,wm−1 – the model tries to predict the probability distribution for the next word wm.
Concisely, the model predicts the probability for the next possible word.
For example, completing the sentence: “The aroma of freshly baked bread always makes me feel ________.” involves predicting the word, tokens forming a word, or phrase to fill in the blank.
Examples of early research and implementation of language models are ‘Markov Chain’1 and ‘n-gram model’2. Those approaches were limited by short memory. Meaning, they struggled to create text that sounded natural over longer passages.
Large Language Models (LLMs)
A pivotal development in language modelling was the introduction of the Transformers architecture in 2017. Transformers are designed around the concept of self-attention, allowing transformer cells to process longer (in this case text) sequences effectively. By focusing on the most relevant parts of the input, Transformers overcome memory limitations that earlier models faced. If you want to dig deeper, you might want to check out the “Attention is all you need” paper.3
LLMs are Transformer-based neural network models4 with a massive number of parameters (the values the model learns during training). These models are trained on enormous datasets of text, providing them with a deep understanding of language structure and nuance.
So, the question is: How large is large?
- The definition of “large” varies, but it encompasses models like BERT(large) (with 340M parameters), PaLM 2 (with up to 340B parameters), and GPT3 with 175B parameters. 5
RAG for Q&A Chatbots: Why does it work?
Chatbots need both knowledge and the ability to communicate in a human-like way. The RAG approach blends a knowledge base (your prepared documents) with the natural-sounding text generation of LLMs.
We can dissect the process in these steps:
- Data ingestion and preprocessing
- Split the data into chunks and convert to text embeddings
- What are text embeddings?
- What is semantic search?
- Store the embeddings in vector store database
- Populate the prompt template
- Send populated prompt template to LLM
- Get response from LLM
Before we start, we can visualise the process using this informal diagram:
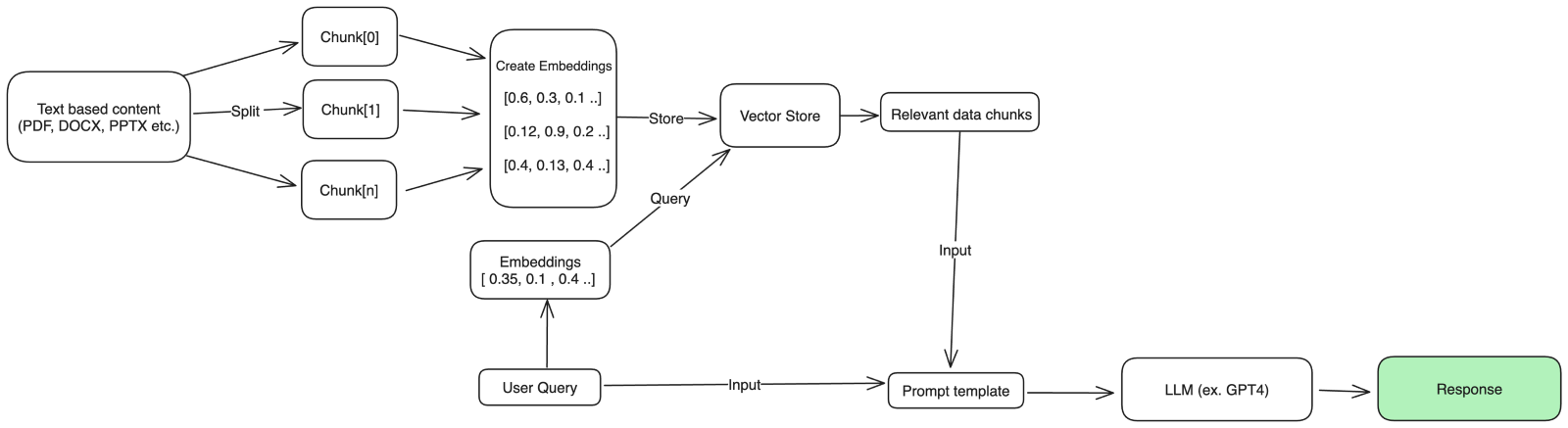
We will use the “LangChain”6 framework which is a high level framework specialised in developing applications powered by language models.
1. Data Ingestion and Preprocessing
- Before we can create an intelligent chatbot, we need data. Collect relevant documents, articles, or any text corpus related to the domain you want your chatbot to specialise in.
- Clean and preprocess the data by removing repeating headers and footers in documents, sanitise the structure of the text (for example normalise the way bullet points are presented across documents, remove unneeded whitespace between pages etc).
2. Splitting Data into Chunks and Generating Text Embeddings
Because we are dealing with a token limit on LLM prompt/input level we need to handle large documents by splitting them into smaller chunks. Next, we need to convert these chunks into text embeddings.
What are Text Embeddings?
Text embeddings are dense vector representations of words or sentences. They capture semantic meaning and context. These embeddings allow us to compare and measure the similarity between text fragments. In our demo example we will use the OpenAI embeddings7 service with the LangChain library to extract embeddings from our documents.
3. Storing Embeddings in a Vector Store Database
A vector store database (also known as an embedding index) stores the text embeddings efficiently. It allows fast retrieval during search operations. Popular choices include Faiss, Chroma, and Pinecone.
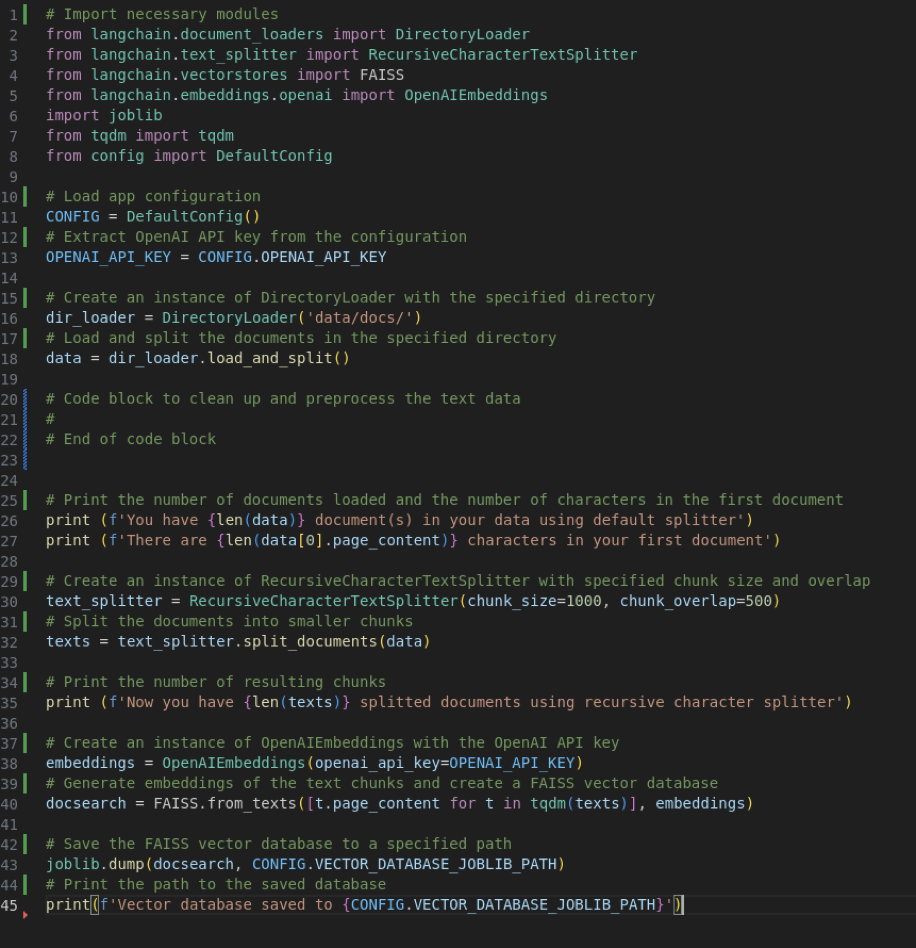
Here’s a code example using LangChain to cover steps 1-3:
4. Semantic Search
Semantic search8 leverages text embeddings and similarity search to find relevant documents or passages. Similarity search is achieved by using similarity metrics as Euclidian distance between the vectors, cosine similarity, etc.
As an example, cosine similarity measures the cosine of the angle between the vectors. A value close to 1 indicates high similarity, while 0 means no similarity.
The library (Faiss) we are using in the example is using Euclidian distance as a default similarity metric.
Given a user query, the chatbot retrieves the most similar chunks of text from the dataset.
5. Populating the Prompt Template
The prompt template contains placeholders for user queries, retrieved passages, and another context. It is the chatbot’s canvas for constructing responses.
6. Sending Populated Prompt Template to Large Language Model (LLM)
Now comes the magic! We send the populated prompt template to a powerful language model (such as GPT-4). The LLM generates a coherent and context-aware response.
7. Receiving the Response
The chatbot receives the LLM’s response and presents it to the user. Voilà! Our Q&A chatbot is ready to engage in meaningful conversations.
The RAG method combines the best of both worlds – retrieval for accuracy and generation for creativity.
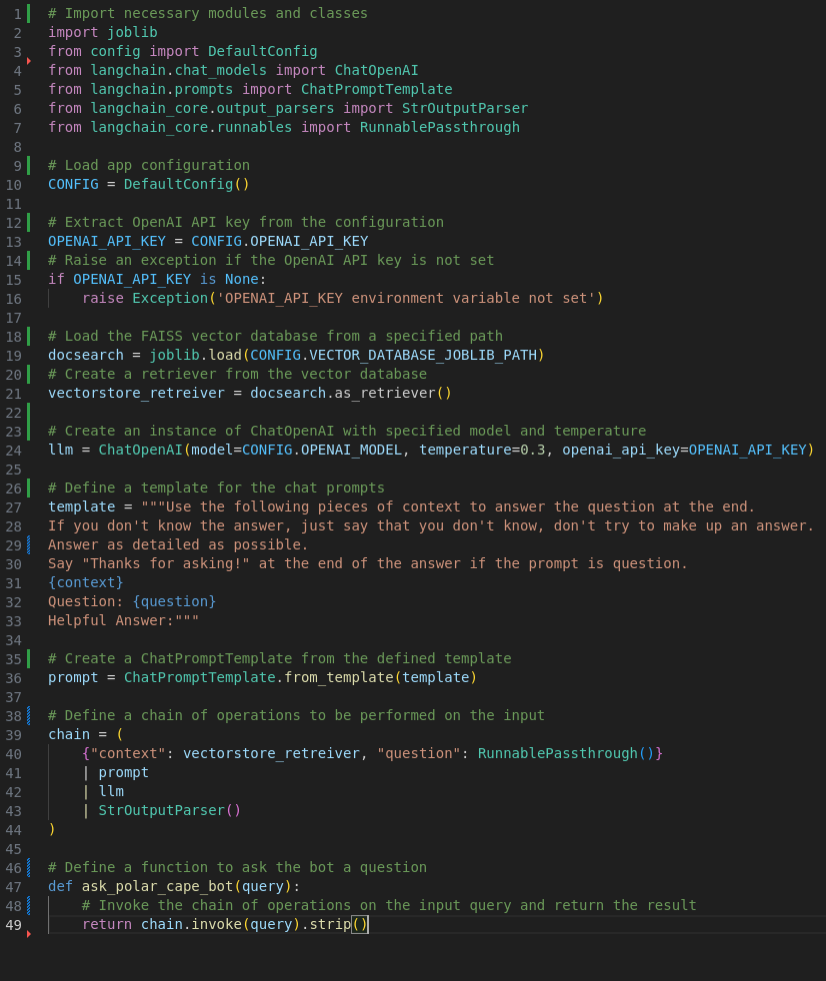
Here is a code example which covers the steps from 4 to 7:
Our Internal LLM & RAG-Based Chatbot
Our internal Polar Cape chatbot was built as described in this post. We use it to streamline employee information access, leveraging the power of Large Language Models (LLMs) and the Retrieval-Augmented Generation (RAG) technique. Our bot taps into a knowledge base of company policies, FAQs (Frequently Asked Questions), and process documentation. LLM capabilities allow it to understand nuanced queries and naturally frame its responses. For example, rather than just linking to HR procedures, the RAG method empowers our chatbot to deliver concise summaries and directly answer questions about benefits, leave policies, etc. This combination makes the chatbot an intuitive and powerful self-service resource for employees.
Conclusion
In this post, we have explored the power of Large Language Models and the RAG method for building sophisticated Q&A chatbots. By combining knowledge retrieval with the generative capabilities of LLMs, we can create bots that sound natural and provide highly informative responses.
Building an exceptional chatbot is an ongoing process. Start with a well-defined domain, gather, and process your data carefully, and be prepared to refine your RAG implementation, prompts, and choice of LLM over time. Each iteration will bring your chatbot closer to becoming a tremendously helpful and engaging conversational partner.
- Von Hilgers, Philipp, and Amy N. Langville. “The five greatest applications of Markov chains.” Proceedings of the Markov Anniversary meeting. Boston, MA: Boston Press, 2006, ↩︎
- Steffen Bickel, Peter Haider, and Tobias Scheffer. 2005. Predicting Sentences using N-Gram Language Models. In Proceedings of Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing, pages 193–200, Vancouver, British Columbia, Canada. Association for Computational Linguistics, https://aclanthology.org/H05-1025/ ↩︎
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. CoRR, 2017, http://arxiv.org/abs/1706.03762, arXiv:1706.03762 ↩︎
- NVIDIA blog, What Is a Transformer Model? https://blogs.nvidia.com/blog/what-is-a-transformer-model/ ↩︎
- Kazi, S. (n.d.). Top Large Language Models (LLMs): GPT-4, LLaMA 2, Mistral 7B, ChatGPT, and More – Vectara. Vectara. ↩︎
- Langchain. (n.d.). https://python.langchain.com/docs/get_started/introduction ↩︎
- OpenAI Platform. (n.d.). https://platform.openai.com/docs/guides/embeddings ↩︎
- What is Semantic Search? | A Comprehensive Semantic Search Guide. (n.d.). Elastic. https://www.elastic.co/what-is/semantic-search ↩︎




